Blob computing
|
|
|
|
|
|
|
|
|
|
Blob computing
|
|||||||||||
|
||||||||||||
|
1st
system level Blob Division on a cellular automata
|
2nd
programmable level Self Developping and self mapping netword
|
|
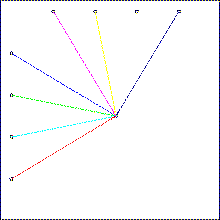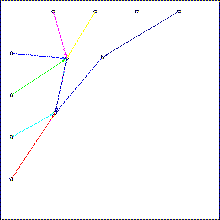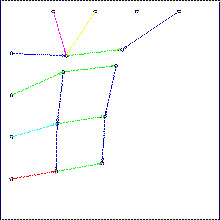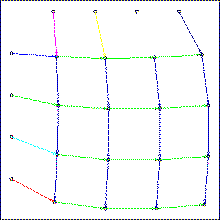
In the first system level a local rule (pre-programmed) can maintain global connected regions called blobs. A blob is similar to a deformable elastic balloon filled with a gas of particles. Each hardware processing element can host one particle. Blobs can also be interconnected. The rule cause Blobs to move, duplicate or delete themselves, and propagate signals like wave. |
|
In the second programmable level each particle contains an elementary piece of data and code, and can receive, process or send signals. The set of particles contained in a given blob encodes a user-programmed finite state automaton with output action (i.e machine instruction) including duplicate-blob, delete-blob, duplicate-link, delete-link. Execution starts with a single ancestor blob that divides repeatedly, and generates a network of blobs. Thus, a higher level virtual machine called "self developing automata network" is installed on top of a low level uniform computing medium. |
Overview of the project
The following presentation summarizes the project challenges. We present the motivation, and state of the art. Next, we outline “self developing automata network” by listing its specific features that ensure programmability, parallelization, and performance. The fine grain blob machine is presented last, as the most promising option to fit self-development, while allowing scalability.
The “sequential dogma” obsolete: New technologies offer ever increasing hardware resources that make the traditional so called “sequential dogma” obsolete. Both our favoured programming languages and personal computers reflect a sequential dogma: on the software level, we use a step-by-step modification of a global state. On the hardware level, we partition the machine between a very big passive part: the memory and a very fast processing part: the processor. While this dogma was adapted to the early days of computers (it can be implemented with as little as 2250 transistors), it is likely to become obsolete as the numbers of resources increases ( billions of transistors ).
Parallel computing has inherent limitations. The parallel computers can currently exploit those resources, using parallelizing compilers. However they fail to combine scalability and general purpose programability. There exists already parallel machine model which can grow in size, as more hardware resources become available, and can solve bigger tasks quicker (scalability). However, the difficult problem that remains to solve is to make sure the machine can be programmed for a wide variety of tasks (programmability) and the programs can be compiled to execute in parallel (parallelization) without loosing too much time in communication (performance). Most existing approaches limit scalability (a few dozens of processors) and programmability (regular nested loops working on arrays). Parallelization is automated using intelligent compilation, and finally, a concrete performance result is obtained on existing machines. The sequential dogma is still there, both in the programming model, and in the machine execution model.
The brain does go beyond these limitations: The brain illustrates other architectural principles able to exploit massive parallel resources while also allowing a kind of general purpose capability. Biological systems in general are not inherently limited in scalability. Examples are: the molecular machinery of a cell (add more molecules), or the neurons of a brain (add more neurons). Furthermore, the brain does have the ability to perform a wide variety of tasks (programmability), involving sensing and actuating in the real world, that are very difficult for a traditional computer. We are interested at the architectural principles explaining the brain performances, rather than the machine learning capability which is more the “software level”. Indeed, those systems follow a truly non-sequential dogma:
Another important principle needed for computing in the real world is the adequation between structure and functionality: the brain architecture itself i.e. the specific patterns of interconnections between the processing elements (the neurons) is adapted to the task being performed.
Exploring new architecture principles: The blob computing project explores the architecture principles of a scalable and programmable machine model. We postulate that in the long term, the increasing number of hardware resources will enable us to tackle real world computing. However, the price to pay is to throw away the sequential dogma, and adapt new architectural principles. Our research goal is to propose a machine model that can push scalability to some billions of Processing Elements, without limiting programmability to simulation or scientific computations. This goal is difficult; furthermore, the hardware resources needed are not yet available, so we are working on the theory. We have the concept underlying the machine. We focus on proving those concept either with mathematics, or by simulating building blocks - machine parts. The model includes original algorithms to achieve parallelization, with optimal theoretical performance results.
Programmability: a description that is both spatial and dynamic. The language specifies the parallel development of a network, node by node. Thus it describes an object existing in space, i.e a circuit, without sacrificing the capability of dynamic instantiation, needed for programmability. To exploit a huge amount of hardware resources, we need to develop computation in space, rather than in time, by reusing a bounded piece of hardware. We have to specify circuits which are spatially laid out, and implicitly parallel. However, few algorithms can be programmed into a fixed size, static, VLSI circuit. To provide more programmability, our language presents an added mechanism, allowing dynamic instantiation of circuits. It does not only describe circuits, but also how to develop them, from an initial ancestor node, that can repeatedly duplicate or delete itself, and its links. Moreover, the shape of the developed circuits is not restricted to the crystalline structure of the task graphs associated to affine nested loops. It is programmed and therefore adapted to the specific targeted functionality; the adequation between structure and function (a property of the brain) is the key to build “real world computing” machines. The programmability has two practical foundations:
Parallelization: no parallelizing compiler is needed: the user has to “fold” a task graph into a “self-developing automata network” which is distributed by the machine itself, at run time. The state of the machine represents a circuit or network. More precisely the nodes of this network are not logic gates, but finite automata with output actions. The automata network is in fact self developing. The automaton's action can duplicate or delete itself (or its connections). These actions are directly machine instructions interpreted in hardware. As a result, the machine language itself keeps a semantic fully parallel:
There is no shared memory, or even a global name space. Who communicates with who, this is thus clearly represented at any time by the network itself, and can be exploited by the machine to automatically map the network on its hardware, at run time. The parallelization effort is shared between the user and the machine. As a result, no intelligent compilation is needed for parallelization.
Performance can be theoretically optimal. Simulation of physical law continuously migrates data and code throughout the hardware so as to optimize communication latency and load balancing. The machine architecture has a 2D or 3D shape and its state represent an automata network in the underlying 2D or 3D space. Physical forces are simulated: Connections act as springs, pulling nearer any pair of communicating automata to reduce communication latency. Another repulsive force between automata homogenizes the density of automata distribution which naturally provoke load balancing. Such technique already exists, but here, the combination with a step by step development prevents the plague of local convergence. Indeed, the adjustment needed at each step is sufficiently simple, that automata are directly attracted towards their new optimal position. There are no sub-optimal basins of attraction. Assuming a set of reasonable hypothesis (already tested in some classic cases such as sort, or matrix multiply), the theory predicts optimal asymptotic performance results (up to a constant factor), in the VLSI complexity model.
Scalability implies fine grain. A fine grain machine better support the dynamic migration of code and data, and is more promising for hardware salability. A blob machine could be coarse grained: each Processing Elements (PE) would then simulate a subnet of the self-developing automata-network. However, we prefer the converse: a fine grained machine where each automaton is simulated by a set of PEs, forming a connected region called blob. First of all, a medium grain (one automaton per PE) would impose an upper bound on the size of each automaton. Second, because the data and the code of each automaton keeps moving across the PEs, it is crucial to minimize the associated communication cost. In the fine grained model, moving a blob can be done in a pipelined way, and using as many wires as the blob diameter. Third, the time cost taken for simulating the action of physical forces can be replaced by a hardware cost. Indeed, those forces are intrinsically local, and can be described by differential equation, of which a discrete form leads to simple local rules (like cellular automata) implemented directly by circuits in hardware . Fourthly, a fine grain model such as the amorphous machine has far more potential for scalability: A machine is seen as a fault tolerant computing medium, made of billions of small identical PEs, identically programmed, with only connections between nearby neighbors, without central control, nor requirement of synchrony or regular interconnect. Nanotechnologies could offer such perspective. Finally, it is also an attractive scientific challenge to find out what is the smallest hardware building block enabling both scalability and programmability.